

Cos’è GFS
GFS è un file system condiviso sviluppato da RedHat compatibile con molte piattaforme di storage e server. Consente ad ognuno dei nodi connessi di accedere a questo FS in lettura e scrittura contemporaneamente aumentando le performance degli stessi nodi. Non presenta punti singoli di fallimento grazie alla replicazione dei dati sui vari nodi connessi, in più è scalabile quindi consente l’aggiunta di ulteriori nodi riducendo al minimo la gestione dell’intero sistema. Supporta le applicazioni standard Linux senza l’esigenza che ognuna conosca la struttura sottostante, quindi come se fosse in locale. Questa struttura consente molte opzioni come la gestione dello spazio (quota), percorsi multipli per accedere alle risorse consentendo alta affidabilità e ridondanza dei servizi, nonchè il bilanciamento del carico di lavoro tra i nodi per quelle applicazioni che richiedo molte risorse (file serving, web, email, database).
Esempi di implementazione
Questo sistema consente di creare diverse configurazioni in base agli obiettivi da raggiungere ma anche dalle risorse hardware ed economiche disponibili. Per una configurazione dove sono necessarie elevate performace si possono creare vari nodi (per un massimo di 300), sul quale far girare le applicazioni, connessi direttamente ad una SAN in modo che i file siano disponibili per tutti i nodi sfruttando la velocità offerta da connessioni iSCSI o FiberOptic.
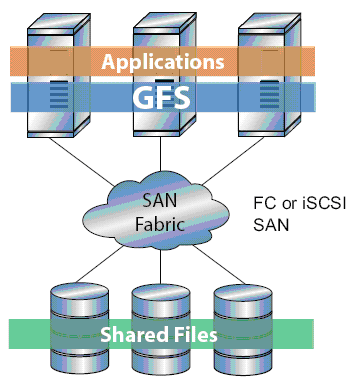
Per soluzioni di elevate performace ma con un costo decisamente minore si può creare una struttura di nodi connessi tramite LAN a dei server di rete, basati su GNBD, i quali sono connessi alla SAN. Per i nodi è come se fossero direttamente connessi alla SAN.
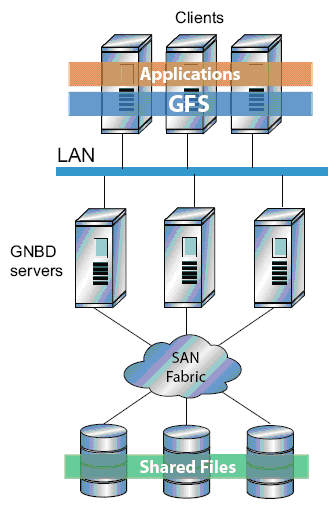
Per una soluzione “economica” si può scegliere di connettere i nodi tramite LAN a dei server di rete basati su GNDB sui quali risiedono i dati.
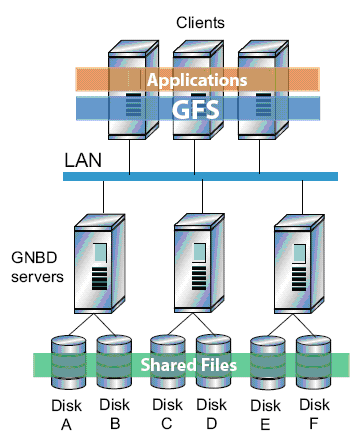
Requisiti Hardware e Software
GFS è supportato da sistemi con SO RedHat basati su kernel della serie 2.4.x. La tabella di seguito mostra i vari SO supportati con le architetture delle CPU e requisiti RAM.

Una connessione in rete tra i vari nodi è essenziale per il funzionamento del cluster stesso, per tutte quelle funzioni che ne regolano il funzionamento e l’accesso ai dati nel caso i cui non vi sia una connessione hardware ai sistemi di storage (Figura 2 e 3). Per tanto è consigliabile disporre di una rete privata e dedicata per la connessione tra i nodi.
Connessione ad alimentatori di rete
Con GFS sono forniti una serie di strumenti per la connessione a sistemi di alimentazione di rete come APC e WTI
Installazione di un sistema GFS
Come detto in precedenza occorrono dei sistemi con SO RedHat sul quale installare GFS e le dipendenze (perl-Net-Telnet module, Clock synchronization software, Stunnel utility). Il modulo perl-Net-Telnet serve ai software di FENCING è deve essere installato prima di GFS. Lo si trova nel cd-rom di installazione del SO oppure su CPAN. Il software di sinccronizzazione del tempo fa si che su tutti i nodi ci sia una sincronizzazione del timer di sistema evidando così gli update degli inodi quando non necessario in modo da ottimizzare le performance del cluster. Un esempio di software per questa funzione è Network Time Protocol (NTP) già disponibile in molte versioni di Linux o reperibile in rete all’URL http://www.ntp.org L’installazione di GFS avviene tramite RPM, quindi con il controllo automatico delle dipendenze. I pacchetti da installare sono due: GFS e GFS-modules. Il primo comprende tutto l’insieme di tools necessari al funzionamento di GFS, il secondo applica una serie di patches al kernel installato, proprio per questo motivo occorre prestare attenzione alla versione che si usa che deve essere per il kernel in uso. Un esempio di comandi console per l’installazione dei due pacchetti sono riportare di seguito:
rpm -Uvh GFS-6.0.2.20-1.i686.rpm rpm -Uvh GFS-modules-smp-6.0.2.20-1.i686.rpm rpm -qa | grep GFS
Una volta che i pacchetti sono stati installati occore cominciare a caricare vari moduli necessari per il funzionamento. Tali moduli devono essere caricati ad ogni avvio del sistema per tanto si consiglia di usare degli script che ne consentono l’avvio gestito da INIT. Per un avvio manuale si possono usare da console i comandi riportati di seguito:
depmod –a modprobe pool modprobe lock_gulm modprobe gfs
Configurazione iniziale
Configurazione dei volumi logici (Pool)
Pool è un software di gestione dei volumi logici per sistemi cluster. La sua funzione è quella di far vedere dei volumi fisici, come dischi o array, come se fossero dei volumi logici direttamente connessi al nodo e dato che li gestisce a livello globale, le modifiche effettuate su di un nodo sono visibili dagli altri. Pool comprende una serie di comandi ognuno con una funzione specifica. Pool_tool fornisce una serie di funzioni di gestione dei volumi, come l’aggiunta, la rimozione, rinomina e stampa della della configurazione. Prevede una serie di opzioni che ne determinano una funzione specifica, di seguito sono riportate le opzioni con la descrizione della funzione svolta.
-c # Crea un nuovo pool -e # Cancella un pool -s # Scansione dei device del pool -g # Aggiunge device ad un pool esistente -r # Rinomina un pool esistente -p # Stampa la configurazione -m # Cambia il Pool Volume Minor Number -D # Abilita il debug -h # Mostra l'help -o # Override prompts -v # Abilita la modalità verbose -V # Mostra la versione -q # Non mostra alcun output
Pool_assemble attiva o disattiva i pool sul sistema, consente di specifica i nomi dei pool sul quale eseguire le operazioni richieste, se non specificato agisce su tutti i pool presenti, di seguito sono riportate le opzioni con la descrizione della funzione svolta.
-a # Attiva un pool -r # Disattiva un pool -D # Abilita il debug -h # Mostra l'help -v # Abilita la modalità verbose -V # Mostra la versione -q # Non mostra alcun output
Pool_info scansiona i device e mostra le informazioni sui pool attivi, possono essere inseriti i nomi dei pool per visualizzare solo le informazioni di un determinato pool, di seguito sono riportate le opzioni con la descrizione della funzione svolta.
-c # Cancella le statistiche -i # Mostra le informazioni -s # Mostra le statistiche -p # Mostra la configurazione attiva -D # Abilita il debug -h # Mostra l'help -H # Mostra la capacità -t # Setta il tempo per gli aggiornamenti delle statistiche -v # Abilita la modalità verbose -V # Mostra la versione
Pool_mp gestisce i percorsi multipli verso le risorse per i pool attivi, di seguito sono riportate le opzioni con la descrizione della funzione svolta.
-m # Corregge i percorsi -r # Ripristina i percorsi falliti in precedenza -D # Abilita il debug -h # Mostra l'help -v # Abilita la modalità verbose -V # Mostra la versione -q # Non mostra alcun output
Creazione della configurazione per un nuovo volume
Questo file di configurazione è usato da pool_tool per tutte le sue operazioni. Il nome del file può essere arbitrario e per più volumi può essere numerato in progressione (pool0.cfg). Tale file contiene cinque campi che descrivono una funzione precisa: poolname, minor, subpools, subpool, pooldevice
poolname pool0 # Indica il nome del pool minor 1 # Imposta il Minor Number subpools 1 # subpool 0 128 2 gfs_data # pooldevice 0 0 /dev/sda1 # Indica il device che fa parte del pool pooldevice 0 1 /dev/sdb1 # Indica il device che fa parte del pool
Una volta creato il file di configurazione si può procedere con la creazione del pool di device tramite il comando seguente:
pool_tool -c pool0.cfg # Crea un pool
Adesso che il pool è stato creato occore attivarlo tramite il comando:
pool_assemble -a pool0 # Attiva il pool 'pool0'
Per verificare lo stato dei pool usiamo il comando:
pool_tool -p pool0 # Mostra lo stato per il pool 'pool0'
Per aggiungere un nuovo pool, basta creare un nuovo file di configurazione ed eseguire il comando:
pool_tool -g pool1 # Aggiunge il pool 'pool1'
Per eliminare un pool esistente digitiamo:
pool_tool -e pool0 # Rimuove il pool 'pool0'
Per rinominare un pool esistente:
pool_tool -r pool0 new_name # Rinomina il pool 'pool0' in new_name
Per modificare il Minor Number:
pool_tool -m 2 pool0 # Imposta Minor Number '2' per il pool0
Per visualizzare le informazioni:
pool_info -i pool0 # Mostra le informazioni per il pool0 pool_info -v pool0 # Mostra le informazioni complete
Per visualizzare le statistiche:
pool_info -s pool0 # Mostra le statistiche per il pool0 pool_info -c pool0 # Cancella le statistiche per il pool0
Per gestire i percorsi fisici verso lo storage:
pool_mp -m none pool0 # Imposta il percorso per il pool0 pool_mp -m failover pool0 # Imposta il percorso per il pool0 pool_mp -m 256 pool0 # Imposta il percorso per il pool0 pool_mp -r pool0 # Ripristina i percorsi per il pool0
Creazione della configurazione del cluster
Per la configurazione del cluster occorrono tre file di configurazione diversi opportunamente chiamati:
cluster.ccs # Contiene il nome del cluster e dei nodi che ne fanno parte fence.ccs # Contiene i device utilizzati per il fencing nodes.ccs # Contiene le informazioni sui singoli nodi
Prima di cominciare con la creazione dei file di configurazione occorre fermarsi su alcuni punti critici:
- Nome del cluster
- Creazione di una directory temporaneo che conterrà i file di configurazione (/root/cluster_config/)
- Se i nodi hanno un sistema dual-power o percorsi multipli verso lo storage
- Se verrà usato un sistema con GNBD
- Identificare i nodi che usano il server LOCK_GULM
- La tipologia di fencing per ogni nodo
Considerazione su sistemi di fencing per Dual Power e Multipath FC
Per essere sicuri che un sistema con doppia alimentazione o con percorsi multipli verso l’area di storage è fondamentale che tutto sia riportato nella configurazione, nei file fence.ccs e nodes.ccs specificando tutte le informazioni per l’accesso ai device (agente, porta, percorsi, ip, ecc). Soltanto gli APC MasterSwitch gestiscono macchine con doppia alimentazione, mentre i percorsi multipli verso lo storage sono supportati sia da switch Brocade che Vixel.
Considerazioni sui percorsi multipli per GNBD
GNBD offre ai nodi GFS una connessione al sistema di storage. La configurazione di mercorsi multipli a più server GNBD consente ai client (nodi GFS) di raggiungere sempre l’area di storage tramite altri server GNBD nel caso in cui quello predefinito ha problemi, così da permettere una continuità nel servizio. Quando si configura il file fence.css è importante far in modo che:
- in caso di fail di un server GNBD esso venga rimosso dalla rete
- se viene definita l’opzione fence_gnbd bisogna definire il parametro multipath
Creazione del file di configurazione cluster.ccs
Questo file deve contene alcuni parametri fondamentali:
- In nome del cluster
- I nomi dei nodi che ne fanno parte che usano LOCK_GULM
Di seguito è riportato un esempio di questo file
cluster {
name = "test"
lock_gulm {
servers = ["nodo1", "nodo2"]
heartbeat_rate = 10 # Parametro opzionale
allowed_misses = 2 # Parametro opzionale
}
}
Creazione del file di configurazione fence.ccs
In questo file vanno definiti tutti i device che faranno parte del dominio di fencing (APC MasterSwitch, xCAT, FC switch, GNBD, ecc). Questi device sono anche presenti nella configurazione dei nodi. Per ogni device esiste un tool che gestisce il device (agent) che viene specificato in base al device utilizzato. Di seguito sono riportati i nomi degli agent per i device comunemente utilizzati:
- APC MasterSwitch # fence_apc
- WTI NPS # fence_wti
- Brocade FC-switch # fence_brocade
- McData FC-switch # fence_mcdata
- Vixel FC-switch # fence_vixel
- GNBD # fence_gnbd
- HP-RILOE-card # fence_rib
- xCAT # fence_xcat
- Egenera BladeFrame # fence_egenera
Degli esempi di configurazione per i vari device sono riportati di seguito
fence_devices{
DeviceName {
agent = "fence_apc"
ipaddr = "IPAddress"
login = "LoginName"
passwd = "LoginPassword"
}
}
fence_devices{
DeviceName {
agent = "fence_wti"
ipaddr = " IPAddress"
passwd = " LoginPassword"
}
}
fence_devices{
DeviceName {
agent = "fence_brocade"
ipaddr = "IPAddress"
login = "LoginName"
passwd = "LoginPassword"
}
}
fence_devices{
DeviceName {
agent = "fence_mcdata"
ipaddr = "IPAddress"
login = "LoginName"
passwd = "LoginPassword"
}
}
fence_devices{
DeviceName {
agent = "fence_vixel"
ipaddr = "IPAddress"
passwd = "LoginPassword"
}
}
fence_devices{
DeviceName {
agent = "fence_gnbd"
server = "ServerName"
option = "multipath"
retrys = "Number"
wait_time = "Seconds"
}
}
fence_devices{
DeviceName {
agent = "fence_rib"
hostname = "HostName"
login = "LoginName"
passwd = "LoginPassword"
}
}
fence_devices{
DeviceName {
agent = "fence_xcat"
rpower = "RpowerBinaryPath"
}
}
fence_devices{
DeviceName {
agent = "fence_egenera"
cserver = "CserverName"
}
}
Creazione del file di configurazione nodes.ccs
Questo file contiene la configurazione per i singoli nodi GFS che faranno parte del cluster. Per ognuno sono definiti:
- Nome
- IP
- Interfaccia
- Tipo di fencing
- Impostazioni per il device scelto
nodes {
NodeName {
ip_interfaces {
IFNAME= "IPAddress"
}
fence {
MethodName {
DeviceName {
port = PortNumberswitch
switch = SwitchNumber
}
}
}
}
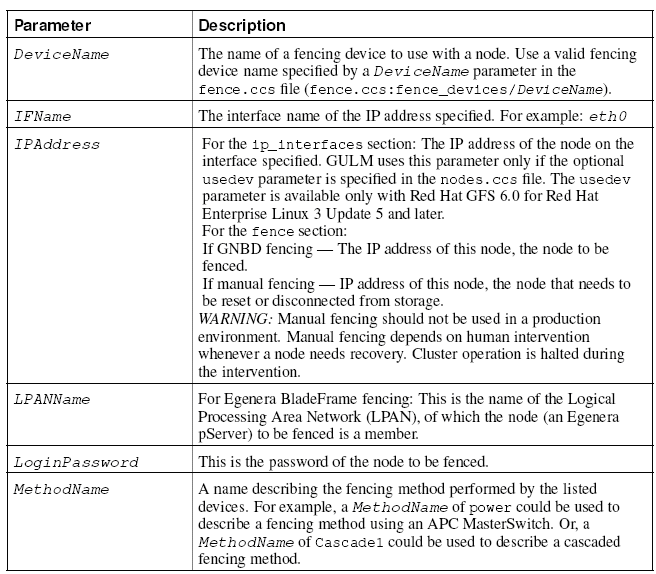


Cluster Configuration System
Creazione ed uso di un archivio CCS
Creare un archivio di file di configurazione ccs ne permette la condivisione tramite tutti i nodi del cluster che vengono memorizzati in un pool condivico CCA device. L’archivio puo essere creato mediante l’uso del comando ccs_tool:
ccs_tool create temp_dir CCAdevice ccs_tool create /root/cluster_config/ /dev/pool/test_cca
Una volta creato l’archivio bisogna far sapere a tutti i nodi dell’esistenza e della posizione dell’arcivio stesso. Su ogni nodo deve essere eseguito il comando:
ccsd -d /dev/pool/test_cca
Tale archivio può essere estratto per acccedere ai singoli file di configurazione con l’ausilio del comando:
ccs_tool extract /dev/pool/test_cca temp_dir
Per avere una lista dei file contenuti nell’archivio si utilizzaerà il comando:
ccs_tool list /dev/pool/test_cca
Tali file di configurazione possono essere comparati tra delle versioni vecchie e nuove, per far ciò possiamo digitare:
ccs_tool diff /dev/pool/test_cca temp_dir
Nel caso in cui debbano essere apportate modifiche ai file di configurazione, tale operazione può essere fatta prima estraendo i file stessi dall’archivio, poi modificandone i valori, per poi ricreare l’archivio
ccs_tool extract /dev/pool/test_cca /root/cluster_config-new/ vi nodes.ccs ccs_tool -O create /root/cluster_config-new/ /dev/pool/test_cca
Uso del sistema di Clustering e di Locking
L’uso del sistema di Locking è reso possibile dall’impiego di due moduli caricati nel kernel (lock_harness.oe gfs.o). Questo sistema di blocco agisce a livello dei singoli nodi che fungono ognuno da server e nel caso di fail del master c’è sempre un nodo in standby che si attiva in modo da offrire continuità al servizio. I nodi che saranno dei server LOCK_GULM sono specificati nel file cluster.ccs. Per ragioni di performance/sicurezza è consigliato l’uso di macchine dedicate per tali server, ma in mancanza si possono come usare server nodi GFS. L’uso di server LOCK_GULM implica l’esistenaza di un unico punto di fail per l’intero cluster, per questo motivo vengono creati più server che restano in standby e si attivano in caso di fail del master. Per garantire un’integrità dei dati il numero minimo di server è fissato a tre e per un massimo di cinque. Nel caso in cui non vi siano presenti server LOCK_GULM è importante chiudere le istanze aperte sui nodi GFS prima che essi vengano riavviati in modo da evitare incoerenze nei dati. Lo stato del cluster è gestito dal demone lock_gulmd che si occupa di gestire le operazioni di fencing prima di avviare le procedure di recovery. Prima di arrestare un server LOCK_GULM master, occorre arrestare il demone lock_gulmd tramite il comando gulm_tool shutdown ip_address/hostname. L’uso di LOCK_NOLOCK consente al nodo di gestire GFS in locale, per tanto ne è sconsigliato l’uso su più nodi in modo da evitare incoerenza nei dati
Gestione di GFS
Una volta che tutta la configurazione è stata portata a termine, l’ultima fase è quella della creazione del file system GFS, che verrà attivato e gestito come pool dal Volume Manager. Per la creazione del file system occorrono tre elementi:
- molulo di locking
- nome del cluster
- numero dei nodi
Il comando per la creazione del file system è:
gfs_mkfs -p LockProtoName -t LockTableName -j Number BlockDevice
LockProtoName # Indica il modulo da usare LockTableName # Indica il nome del cluster e l’identificativo del file system Number # Indica il numero di nodi BlockDevice # Indica il punto di accesso al device
gfs_mkfs -p lock_gulm -t test:gfs1 -j 2 /dev/pool/pool0
Di seguito sono riportate degli switch che possono essere usati con il comando precedente
-b # Imposta le dimensioni del blocco (default 4096) -D # Abilità la funzione di debug -h # Mostra l'help -j # Imposta la dimensione in MB per il journal (default 128MB) -J # Imposta il numero di journal (uno per ogni nodo) -P # Specifica che il file system sarà un pool -p # Imposta il nome del modulo da usare -o # Non chiede conferma per le opernazioni -q # Non mostra alcun output -r # Imposta la dimensione per il resource group (default 256MB) -s # Imposta la dimensione del segmento di journal -t # Imposta il nome del cluster e l'identificativo del file system -V # Mostra la versione
Prima di poter montare il nuovo file system, esso deve essere attivato come pool. Una volta che tali operazioni sono state portate a termine, si può procedere al mounting tramite il comando:
mount -t gfs BlockDevice MountPoint
BlockDevice # Indica la posizione del pool MountPoint # Indica il punto di accesso al nuovo file system
mount -t gfs /dev/pool/pool0 /gfs1
Per smontare il file system si usa il comando:
umount /gfs1
Gestione dello spazio disco (Quota)
Come per un qualsiasi file system, anche per GFS è possibile limitare lo spazio a disposizione di un utente o gruppo. Tale operazione è compiuta sia per questioni di sicurezza sia per la gestione delle performance dell’intero sistema, con l’ausilio di un tool specifico per GFS in quanto è l’unico che lo supporta (gfs_quota). Possono essere impostati due livelli di limite: hard e warn. Il primo imposta il limite di spazio che un utente o gruppo può occupare, mentre il secondo imposta un valore inferiore all’hard quota e quando lo si raggiunge viene creato un avviso del raggiungimento della capacità massima consentita. L’hard quota viene impostata tramite il comando:
gfs_quota limit -u User -l Size -f MountPoint gfs_quota limit -g Group -l Size -f MountPoint
Size # Imposta la dimensione in MB MountPoint # Imposta in punto di accesso al file system
gfs_quota limit -u utente1 -l 100 -f /gfs1 gfs_quota limit -g 100 -l 50 -f /gfs1
Per impostare il warn quota:
gfs_quota warn -u User -l Size -f MountPoint gfs_quota warn -g Group -l Size -f MountPoint gfs_quota warn -u utente1 -l 90 -f /gfs1 gfs_quota warn -g 100 -l 40 -f /gfs1
Per visuallizare i limiti impostati e l’utilizzo delle stesse si usano i comandi:
gfs_quota list -f /gfs1 # Visualizza tutti i limiti gfs_quota get -u utente1 -f /gfs1 # Visualizza il limite per l'utente gfs_quota get -g 100 -f /gfs1 # Visualizza il limite per il gruppo
Le informazioni sulle quote vengono memorizzate in un file sul GFS e non viene aggiornato continuamente ma per default ogni 60 secondi. Tale intervallo può essere variato Per evitare problemi è utile sincronizzare le quote su di ogni nodo tramite il comando:
gfs_quota sync -f /gfs1
Di default GFS tiene traccia degli utenti e gruppi per i quali non sono stati impostati i valori di quota. Questo potrebbe rallentare le funzioni del cluster, per disabilitare tale controllo si può utilizzare gfs_tool con il valore 0:
gfs_tool settune /gfs1 quota_account 0
Tale comando deve essere ripeturo ad ogni mount del file system e su ogni nodo.
Espansione dello spazio disponibile su GFS
E’ possibile incrementare le dimensioni del file system GFS, in modo che tutti i nodi abbiano più spazio disponibile per le operazioni. Per tale scopo si utilizza il comando gfs_grow su di un nodo con il file system montato. Dopo questo comando è consigliabile effettuare un controllo sul file system per assicurarsi dello stato dello stesso. E’ ovvio che prima di avviare questo comando bisogna compiere delle operazioni sul pool che contiene GFS, infatti è importante prima di procedere:
- Fare dei backup dei dati importanti
- Avere informazioni sull’utilizzo effettivo del pool (gfs_tool df /gfs)
- Espandere il pool (pool_tool -g)
Per espandere il file system GFS:
gfs_grow /gfs1 # Espande il GFS gfs_grow -Tv /gfs1 # Controlla il GFS
Aggiunta di Journal al GFS
Nel caso di aggiunta di nodi supplementari bisogna aggiungere journal per quanti sono i nodi. Per compiere questa operazione si usa il comando gfs_jadd. Come per l’espansione del file system GFS è consigliato effettuare un controllo dopo l’aggiunta dei journal.
gfs_jadd -j Number MountPoint
Number # Imposta il numero di journal da aggiungere MountPoint # Indica il punto di accesso al quale aggiungere i journal
gfs_jadd -j 2 /gfs1 # Aggiunge 2 journal gfs_jadd -Tv /gfs1 # Effettua un controllo sul GFS
Data Journaling
GFS scrive subito solo i metadata, mentre il contenuto intero di un file è scritto in seguito e progressivamente da sincronizzazioni gestite a livello del kernel.
Setting and Clearing the inherit_jdata Flag
gfs_tool setflag inherit_jdata Directory gfs_tool clearflag inherit_jdata Directory
Setting and Clearing the jdata Flag
gfs_tool setflag jdata File gfs_tool clearflag jdata File gfs_tool setflag inherit_jdata /gfs1/data/ gfs_tool setflag jdata /gfs1/datafile
Configurazione degli update di atime
Sul file system vengono memorizzate oltre alle informazioni contenute in file e directory anche dei parametri come l’ultimo accesso, modifica e cambiamenti. Tali informazioni riguardano tre punti:
ctime # Indica l'ultima volta che l'inodo ha subito cambiamenti mtime # Indica l'ultima volta che un file o directory è stata modificata atime # Indica l'ultima volta che un file o directory è stata accessa
Le informazioni scritte da atime sono utilizzate da molte applicazioni, questo implica un rallentamento nelle funzioni di lettura e scrittura. Per ridurre questi effetti è possibile utilizzre due soluzioni: montare i dispositivi senza l’uso di atime oppure impostare un intervallo di update gestito da GFS.
Nel primo caso il comando utilizzato è:
mount -t gfs BlockDevice MountPoint -o noatime
BlockDevice # Indica il percorso che punta al volume MountPoint # Indica il punto di accesso al volume
mount -t gfs /dev/pool/pool0 /gfs1 -o noatime
Nel caso in cui si voglia impostare un intervallo per gli update direttamente gestiti da GFS si tulizza il comando gfs_tool.
gfs_tool gettune MountPoint # Visualizza i parametri modificabili gfs_tool gettune /gfs1 gfs_tool settune MountPoint atime_quantum Seconds # Imposta un intervallo per gli update di atime in secondi gfs_tool settune /gfs1 atime_quantum 300
Sospensione delle attività
Le attività possono essere sospese momentaneamente per poi poter essere riavviate. Per compiere tali operazioni si usano due opzioni relative a gfs_tool:
gfs_tool freeze /gfs # Sospende le attività gfs_tool unfreeze /gfs # Riprende le attività
Visualizzazione di informazioni e statistiche
gfs_tool counters /gfs1 # Visualizza informazioni sul file system gfs_tool df /gfs1 # Visualizza informazioni sullo spazio del file system
Ripristino di un file system
Nel caso in cui un nodo ha dei problemi, grazie al sistema di journaling i dati possono essere ripristinati, ma se un problema simile avviene su un device di storage occorre ricorrere al comando gfs_fsck per il ripristino dei dati. Tale comando può essere utilizzato su di un file system non in uso dai nodi.
gfs_fsck -y /dev/pool/pool0 # '-y' assume la risposta automatica yes a tutte le domande
Uso dei link simbolici
Context-Dependent Path Names (CDPNs) permette di creare link simbolici a directori o file variabili. Il percorso reale alla risorsa viene risolto a livello applicazione. Per la creazione di link simbolici variabili si possono utilizzare le seguenti variabili:
@hostname # Risolve un file o directory reale con la stringa hostname prodotta da echo 'uname -n' @mach # Risolve un file o directory reale con la stringa machine-type prodotta da echo 'uname -m' @os # Risolve un file o directory reale con la stringa operating-system prodotta da echo 'uname -s' @sys # Risolve un file o directory reale con la stringa combinata machine-type e operatin-system prodotta da echo 'uname -m'_'uname -s' @uid # Risolve un file o directory reale con la stringa userID prodotta da echo ‘id –u’ @gid # Risolve un file o directory reale con la stringa groupID prodotta da echo ‘id –g’
Nell’esempio seguente si vuole creare una directory conf sui due nodi che compongono il cluster
nodo1# cd /gfs1 nodo1# mkdir nodo1 nodo2 nodo1# ln -s @hostname conf nodo1# ls –l /gfs1 rwxrwxrwx 1 root root 7 Nov 7 13:16 conf -> @hostname/ drwxr-xr-x 2 root root 3864
Nov 7 13:16 nodo1/ drwxr-xr-x 2 root root 3864 Nov 7 13:16 nodo2/
Avvio di un cluster GFS
Per eseguire l’avvio di un cluster basato su GFS devono essere compiute alcune operazioni su tutti i nodi che lo compongono
- Attivare i pool
- Avviare i demoni CCS
- Avviare i server LOCK_GULM
- Montare i file system GFS
Per automatizzare queste operazioni sono disponibili degli script gestiti da INIT
Arresto di un cluster GFS
Per eseguire lo spegnimento di un cluster basato su GFS devono essere compiute alcune operazioni su tutti i nodi che lo compongono
- Smontare i file system
- Arrestare i server LOCK_GULM
- Terminare tutti i demoni CCS
- Disattivare tutti i pool attivi
Per automatizzare queste operazioni sono disponibili degli script gestiti da INIT
Uso del sistema di Fencing
E’ un meccanismo che si occupa di rimuovere dall’accesso al file system condiviso, quei nodi che per un qualche motivo hanno dei problemi di funzionamento. Questo sistema gestisce sia la rimozione che il ripristino dei nodi. Un sistema di monitoraggio dei nodi controlla il funzionamento degli stessi. Nel caso in cui su di un nodo viene rilevato un problema, tale nodo viene tolto dal cluster rendendo la sua parte di file system non disponibile onde evitare malfunzionamenti ai nodi restanti. In altre parole il sistema di Fencing evita che un nodo con dati incoerenti con quelli degli altri, rientri nel cluster. Il tipo di fencing è specificato nel file di configurazione fence.ccs, come detto prima per ogni device esiste un agente che si interfaccia tra il nodo ed il device stesso.
APC MasterSwitch L’agente fence_apc logga e riavvia la porta di alimentazione a cui è connesso il nodo. Gestisce anche i nodi con doppia alimentazione, questo fa si che il nodo abbia una ridondanza nel caso in cui si presentino problemi ad uno degli alimentatori.

WTI Network Power Switch L’agente fence_wti svolge la stessa funzione dell’APC MasterSwitch solo che non supporta i nodi con doppia alimentazione.

Brocade FC Switch L’agente fence_brocade logga e disabilità la porta a cui è connesso il nodo. Supporta nodi con percorsi multipli.

Vixel FC Switch L’agente fence_vixel svolge la stessa funzione dell’agente fence_brocade.
![]()
GNBD L’agente fence_gnbd disabilita l’accesso all’area di storage per quei nodi che presentano problemi, che una volta risolti vengono riabilitati all’accesso. Al contrario degli altri agenti, questa soluzione non richiede componenti hardware speciali.
ManualIn caso di mancanza di risorse hardware particolari è possibile gestire manualmente il fencing. Tale soluzione è sconsigliata in ambito produttivo
Uso di GNBD
Come detto prima GNBD esporta sui nodi GFS i volumi di storage a cui sono connessi. Tale funzione è svolta sia a livello server che a livello client da due moduli caricati nel kernel gnbd.o e gnbd_serv.o, che vengono utilizzati tramite i comandi:
gnbd_expor # Esporta un volume condiviso sui server gnbd_import # Importa i volumi presenti sui server, come se fossero in locale sui client
Per esportare un volume che sarà condiviso dai client si usa il comando:
gnbd_export -d pathname -e gnbdname options
pathname # Imposta il percorso del device gnbdname # Imposta in nome del volume condiviso options # -o abilita la sola lettura, -c abilita la cache
gnbd_export -d /dev/sda2 -e prova
Per importare un volume sui client si usa il comando:
gnbd_import -i ServerIP/ServerHostname gnbd_import -i nodo1 gnbd_import -i 192.168.0.1
Un sistema basato su GNBD consente ai nodi di avere sempre a disposizione un percorso fisico di accesso al sistema di storage, nel caso in cui un server GNBD abbia problemi. Nell’uso di questa soluzione ci sono degli aspetti da prendere in considerazione:
- Linux cache paging
- Lock server all’avvio
- Posizione dei file CCS
- Metodo di fencing per GNBD
Per il primo punto è fondamentale che l’opzione di caching sia disabilitata per tutti i nodi del cluster (gnbd_export … -c), per evitare incoerenza di dati tra i vari nodi. Per il secondo punto è fondamentale che il server lock_gulmd sia avviato prima che il sistema GNBD sia abilitato. Per il terzo punto, dato che tutto è basato sui file di configurazione CCS e che il server lock_gulmd deve essere avviato prima di GNBD, tali file devono essere accessibili ai nodi. Nel caso in cui si ha una macchina dedicata a GFS i file CCS si possono trovare in più posizioni (Locale, GNBD, Storage). Nel caso in cui si hanno macchine con GFS e server lock_gulmd, server GNBD dedicati, server GNBD con server lock_gulmd e server lock_gulmd i file si devono trovare in locale o su storage. Per il quarto punto è importante che il metodo di fencing ed il relativo agente, sia appropriato al device scelto. E’ possibile far funzionare GFS su server GNBD con delle limitazioni ed a discapito delle prestazioni complessive
- I server GNBD devono avere accesso fisico all’area di storage e non devono importare localmente il volume condiviso
- I server GNBD devono esportare il volume con il caching disabilitano e non lo devono associare a nessun pool
- GFS deve funzionare a livello pool
Uso degli script
Come detto prima per tutta una serie di funzioni (avvio, gestione, stop) è possibile utilizzare degli script che vengono gestiti da INIT e quindi in base ai runlevel di sistema. In fase di installazione dei pacchetti RPM vengono installati gli script predisposti per le funzioni principali. Sotto la directory /etc/init.d/ si trova lo script ‘gfs’ che si occupa dell’avvio, chiusura e gestione di GFS. Insieme agli script vengono anche installati dei wrappers utilissimi per gestire i vari servizi (pool, ccsd, gfs, lock_gulmd). Di seguito sono riportati degli esempi dell’uso di script e wrappers
/etc/init.d/gfs [start|stop|status] service pool [start|stop] service ccsd [start|stop] service lock_gulmd [start|stop] service gfs [start|stop]
Avvio di GFS tramite script
Di seguito vengono evidenziati gli step da seguire per avviare GFS con successo
- Installare GFS sui nodi
- Caricare il modulo pool.o
- Creare un pool
- Attivare il pool creato
E’ possibile inserire una riga di configurazione contenente un elenco dei pool da attivare (POOLS=”…”) nel file /etc/sysconfig/gfs
- Creare un archivio CCS
- Specificare nel file /etc/sysconfig/gfs il percorso dove si trova l’archivio CCS (CCS_ARCHIVE=”/dev/pool/…”)
- Avviare il demone CCSd
- Avviare il server lock_gulmd
- Creare il file system GFS
- Modificare il file /etc/fstab includendo le informazioni per il mount automatico del file system GFS (/dev/pool/pool0 /gfs1 gfs defaults 0 0)
- Avviare GFS
Conclusioni
In questo caso abbiamo approfondito la parte dedicata alla condivisione delle risorse di più macchine che contemporaneamente usano uno spazio disco condiviso su di altre strutture predisposte a questo scopo. Durante il processo di documentazione e tentativi di realizzazione di questo sistema, si sono presentati dei problemi relativi al software da utilizzare, in quanto la RedHat non fornisce insieme alla distribuzione Linux i software necessari ad implementare un sistema GFS. Tali software non sono neanche disponibili in rete su siti di terzi, ma a quanto pare sono solamente disponibili su RedHat previa acquisto del supporto tecnico che consente al cliente di avere a disposizione un’installazione automatica di tutti i pacchetti software necessari. Per tali ragioni sono state tentate strade alternative all’uso di RedHat. Tra le tante prove e ricerche effettuate, è stato riscontrato che l’unica alternativa possibile è nell’uso della distribuzione Fedora Core 4, sistema derivato direttamente da RedHat ma che non prevede supporto tecnico. Tale distribuzione mette a disposizione dell’utente tutto il necessario per realizzare sistemi basati su GFS. L’unica pecca è nella mancanza di documentazione completa che spieghi tutta la procedura da zero per realizzare sistemi GFS. Inoltre dalla versione precedente, 6.0, sono state cambiate molte cose a livello di programmi e di funzioni degli stessi. Il cambiamento più notevole sta nel software di gestione dei volumi disco, infatti la vecchia versione utilizzava Pool come gestore, mentre la nuova versione (6.1) si appoggia a LVM2 con l’ausilio del supporto dedicato ai cluster. Tale cambiamento insieme alla mancanza di documentazione rende GFS 6.1 molto complicato da implementare.


{kind=link}