

Introduzione
Kerberos è un servizio di autenticazione distribuito che permette ad un processo (client) in nome di un utente (user) di provare la sua identità ad un verificatore (verifier) senza spedire dati attraverso la rete che possano permettere ad un intruso o al verificatore stesso di impersonarlo successivamente.
Kerberos fu sviluppato a metà degli anni 80 come parte del progetto Athena al MIT e attualmente è alla versione 5. Essenzialmente Kerberos si basa sull’utilizzo di chiavi per cifrare le informazioni scambiate tra le entitàƒ che partecipano al protocollo di autenticazione.
Il nome Kerberos deriva da Cerbero, il cane a tre teste che sorveglia le porte dell’Ade. La scelta di questo nome fu fatta per riflettere i primi tre obiettivi:
1) Autorizzazione , che si riferisce alla capacità del sistema di determinare se un individuo è autorizzato ad eseguire una certa operazione.
2) Autenticazione , che si riferisce alla capacità del sistema di determinare se un individuo è veramente colui che dichiara di essere.
3) Cifratura, che si riferisce alla capacità del sistema di prevenire che terze parti ascoltino i contenuti di qualunque comunicazione delle due parti o modifichino i contenuti delle comunicazioni.
Facciamo un esempio che illustri la differenza tra l’autorizzazione e l’autenticazione, considerando il processo di imbarco per un volo: Un passeggero che arriva alla porta di imbarco si autentica fornendo la sua patente di guida all’agente addetto, quest’ultimo verifica che il nome letto sulla patente sia lo stesso indicato sul biglietto. Una volta a bordo il passeggero fornisce nuovamente il biglietto di imbarco per ottenere l’autorizzazione a prendere quel volo.
La mutua autenticazione, infine, si concretizza quando entrambe le parti verificano l’identità dell’altro, rifacendoci all’esempio precedente, il passeggero verifica che quella determinata compagnia aerea e quel determinato aereo siano quelli specificati sul suo biglietto e contemporaneamente la compagnia aerea verifica che quel passeggero sia effettivamente quello che lui dice di essere (autenticazione) e se è autorizzato a prendere quel volo (autorizzazione).
Il MIT distribuisce Kerberos liberamente per agevolare la sostituzione dello standard di autenticazione attuale: “autenticazione per asserzione”.
Con l’autenticazione per asserzione quando un utente esegue un programma che accede ad un servizio di rete, il programma (che chiameremo client) asserisce al servizio (server) di essere in esecuzione su richiesta di quel determinato utente.
In pratica l’autenticazione per asserzione si basa sullo scambio tra client e server di una informazione segreta conosciuta da entrambe le parti (generalmente una password). Il problema è che questa informazione segreta, viene trasmessa in chiaro, quindi un utente non autorizzato può intercettare il “segreto” ed utilizzarlo per accedere al servizio.
Il sistema tradizionale ha anche un altro inconveniente, esso non garantisce l’identità dell’utente che accede al servizio, quindi anche quando la fase di “scambio” del segreto può essere evitata è ancora possibile rompere la sicurezza del sistema, mentendo in qualche modo al server.
Consideriamo per esempio l’rlogin di Berkeley, questo software permette ad un utente che utilizzi il client rlogin di accedere ad una workstation remota su cui sia in funzione il server host.
Una delle funzionalità di questo software è quella di poter accedere all’account remoto senza fornire la password.
Se un utente setta correttamente il file .rhost, infatti, il server verificherà l’identità dell’utente basandosi sull’indirizzo di provenienza, e senza richiedere una password concederà immediatamente l’accesso se questo indirizzo è tra quelli autorizzati.
Se un attaccante fosse capace di “mentire” al server rlogin facendogli credere di provenire da un indirizzo “autorizzato” gli verrebbe concesso l’accesso remoto senza alcuna richiesta di password.
L’alternativa di richiedere agli utenti una password per accedere al servizio ha, come abbiamo visto, il difetto di essere suscettibile di intercettazione, come fare quindi?
Kerberos è stato progettato proprio per eliminare la necessità di dimostrare il possesso di informazioni segrete (come le password) per divulgare l’identità di se stessi, basato sul modello di distribuzioni delle chiavi sviluppato da Needham e Schroeder usa la crittografia a chiave simmetrica una chiave per cifrare e per decifrare (crittografia a chiave simmetrica) le comunicazioni tra client e server.
Brevemente diciamo che una routine di cifratura prende in input una chiave per cifrare e un testo in chiaro e restituisce un testo cifrato. Il testo cifrato è incomprensibile ad occhio nudo ed è apparentemente una sequenza casuale di byte. Parimente una routine di decifratura prende in input un testo cifrato e una chiave per decifrare e restituisce se tutto va bene il testo in chiaro.
Come funziona Kerberos
Per comprendere il funzionamento in generale di Kerberos, e per capire come possa riuscire ad autenticare in modo sicuro un utente, prendiamo ancora una volta spunto dalla realtà quotidiana.
Nella vita quotidiana non sono rari i momenti in cui ci viene richiesto di fornire la nostra identità per usufrurire di un determinato servizio.
Quello che facciamo di solito è esibire un certo documento, per esempio la patente di guida, ad un verificatore (ad. es. un vigile), che ci concederà o meno l’accesso ad una risorsa.
Il verificatore accetta la patente perchè si fida della entità (la motorizzazione) che la ha rilasciata, inoltre si basa, per verificarne l’autenticità , sulle caratteristiche fisiche (integrità della foto, mancanza di abrasioni, cancellature etc) e sulle caratteristiche “logiche” (scadenza ancora valida, correttezza dell’indirizzo di residenza). Se il cerfiticato è valido l’autenticazione ha successo.
Kerberos lavora fondamentalmente nello stesso modo. Un caso comune è che un utente abbia bisogno di utilizzare un servizio di rete e che il servizio voglia assicurasi che l’utente sia davvero colui che dice di essere.
Per far ciò l’utente presenta un certificato elettronico (ticket) rilasciatogli da una autorità di autenticazione che ha il compito che nell’esempio precedente è svolto dalla motorizzazione.
Il servizio allora esamina il ticket per verificare l’identità dell’utente e concederà l’accesso in base al risultato di questa analisi. Il ticket deve contenere informazioni collegate univocamente all’utente, in modo che esso, fornendolo al servizio, possa dimostrare implicitamente di essere effettivamente autorizzato ad accedere alla risorsa.
Le assunzioni di Kerberos
Alla base del funzionamento di Kerberos ci sono alcune assunzioni circa il sistema e l’ambiente di lavoro. Innanzitutto si assume che gli utenti non scelgano password “facili” queste potrebbero essere facilmente scoperte da un attaccante tramite un attacco basato su un dizionario di password deboli.
I realizzatori di Kerberos, infatti, consigliano di utilizzare password con caratteri speciali, maiuscole e minuscole, numeri. Un intruso, una volta, scoperta una password può² impersonare l’utente in qualsiasi verifica.
Nello stesso modo Kerberos assume che le workstation o le macchine siano sicure. In altre parole, Kerberos assume che non esista alcun modo per un hacker di posizionarsi tra l’utente e il client per catturare le password in qualche modo, ad esempio utilizzando un software che registri i tasti premuti dall’utente.
Infine si assume che la rete sia “insicura”, cioè che sia possibile spiare le comunicazioni tra gli host. Questa una assunzione debole perchè chiaramente se la rete al contrario fosse “sicura” la sicurezza di Kerberos non sarebbe certo compromessa.
Il servizio di autenticazione
Come abbiamo accennato nei paragrafi precedenti, Kerberos consente uno scambio di messaggi cifrati tra client e server senza che circolino informazioni segrete sulla rete.
Affinchè questo avvenga, ogni utente utente ed ogni servizio dovranno essere dotati di una chiave per un algoritmo “generico” di crittografia forte.
Kerberos supporta solo algoritmi simmetrici, al momento, e quindi useremo la stessa chiave sia per la cifratura che per la decifratura. In questo scenario ogni utente ed ogni servizio sa come decifrare un messaggio cifrato con la sua chiave segreta ma non ha ancora nessun modo per inviare messaggi cifrati ad altri utenti o ad altri servizi perchè non conosce altre chiavi al di fuori della sua.
Nel “mondo” di Kerberos, non c’è differenza tra client e server, e ci si riferisce ad essi con il termine di “Principal”.
E’ cruciale in questo protocollo la figura dell'”Authentication Server” (AS). L’AS conserva in un suo database le chiavi degli utenti e le chiavi dei servizi, quindi è in grado di scambiare con ognuno di essi messaggi cifrati senza che venga scambiata la chiave.
Il suo compito è quello di fornire ad un client che vuole comunicare con un server una chiave di sessione con la quale i due Principal potranno stabilire una comunicazione cifrata, grazie all’AS come vedremo avremo la certezza che solo i due Principal coinvolti nella transazione conoscano la chiave di sessione (insieme all’AS naturalmente) e quindi la comunicazione potrà avvenire in tutta sicurezza. Cosa succede quindi nel dettaglio quando un utente vuole accedere ad un determinato servizio ?
A differenza di quanto accadeva nel sistema tradizionale non c’è una comunicazione diretta client –> server ma la comunicazione è mediata dall’AS e avviene con un fitto scambio di messaggi come segue:

Figura1: Protocollo di base di Kerberos semplificato
Supponiamo che il client voglia accedere al server rappresentato in figura:
1 Inizialmente effettua una richiesta di autenticazione all’AS per l’applicazione desiderata, inviando un messaggio in chiaro che contiene:
- il nome del client che fa la richiesta;
- il nome del server a cui si vuole accedere;
- ed un una data di scadenza calcolata a partire dalla data e dall’ora locale del client;
2 L’AS prepara due copie di una chiave di sessione (Ks) valida per l’algoritmo crittografico scelto e crea due Ticket che invierà indietro al client:
- Uno cifrato con la chiave del server (server key=Kser) per cui è stata fatta la richiesta;
- L’altro cifrato con la chiave del client (client key=Kcli);
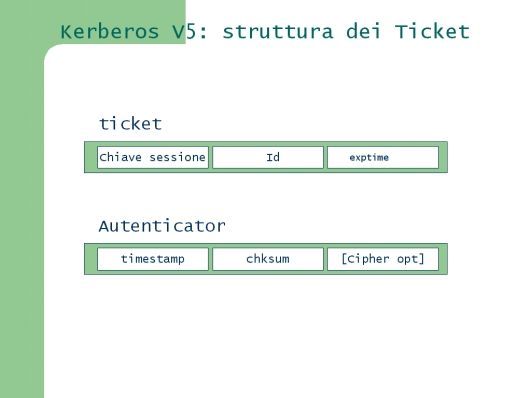
In ogni Ticket c’è una copia della chiave di sessione, c’è la data di scadenza ricevuta dal client, e ci sono i due identificativi. Il Ticket cifrato con Kser conterrà l’Id del client, mentre quello cifrato con Kcli conterrà l’Id del server.
3 Una volta ricevuti i due Ticket da parte dell’AS il client ne decifra uno, quello cifrato con la sua chiave segreta, ed effettua le seguenti operazioni:
- Estrae la chiave di sessione (Ks);
- Prepara un Ticket speciale che chiameremo “Authenticator” cifrato con la chiave di sessione appena estratta;
- Quindi invia al server L’Authenticator e il Ticket che era stato cifrato con la chiave Kser;
L’Authenticator contiene un timestamp calcolato a partire dall’ora locale del client, un chksum e alcune opzioni di cifratura.
4 Il server quindi riceve il Ticket e l’Authenticator, con la propria chiave segreta decifra il Ticket ed estrae la chiave di sessione, con la chiave di sessione decifra l’Authenticator:
– il server può verificare la scadenza della chiave usando l’informazione contenuta nel Ticket, se questa è valida ha la certezza che essa sia stata generata dal AS perchè solo quest’ultimo conosce la sua chiave segreta;
– analogamente decifrando l’Authenticator il server ne verifica l’integrità con il chksum e controlla che esso non sia stato già spedito usando il timestamp in esso contenuto (il server non accetta messaggi con lo stesso timestamp). Questo da la certezza al server che la richiesta sia stata fatta dal “client” associato al Ticket perchè solo lui poteva conoscere la chiave di sessione;
5 Opzionalmente il server può richiedere al client la “mutua autenticazione” che in genere consiste di un messaggio cifrato con Ks contenente il timestamp ricevuto dal client e un numero sequenziale. Anche in questo caso il client accetterà il Ticket solo se esso non contiene un timestamp già visto oppure fuori da una certo arco temporale;
Naturalmente l’uso dei timestamp in un sistema distribuito necessità di una forte sincronizzazione dei vari host partecipanti allo scambio.
Nella seguente figura sono riassunti i campi contenuti nel Ticket e nell’ Authenticator:
Il Ticket Granting Server
In uno scenario come quello appena visto, si prospetta un potenziale problema: per ogni servizio il client dovrà usare la propria chiave “segreta” e questo significa che l’utente dovrà digitare ogni volta la password, perchè come vedremo la chiave segreta è calcolata a partire dalla password.
Il problema in questo caso è che l’utente è normalmente portato a vedere come un fastidio la password ed inserirla spesso lo spinge a usare password deboli; inoltre usare la chiave segreta significa in qualche modo esporla troppo ad attacchi di tipo “Known Cyphertext”.
Per evitare questo inconveniente introduciamo una nuova figura che chiamiamo “Ticket Granting Server” (TGS). La figura seguente è da intendersi come integrazione allo schema visto precedentemente.

Figura3: Protocollo di base di Kerberos
Dal punto di vista del protocollo Il TGS è gestito come un normale servizio di sistema.
Funziona nel seguente modo. Il client che ha appena eseguito la login dovrà richiedere all’AS un Ticket per comunicare con il TGS. L’AS (come abbiamo visto prima) manda al client due Ticket con la chiave di sessione Ks, uno cifrato con Kcli e un altro con KTGS (la chiave del TGS). Dopo ciò il client effettuerà la richiesta al TGS (come in figura) mandando il Ticket cifrato con KTGS e l’Autenticator. Questo Ticket è chiamato Ticket Granting Ticket (TGT) ed ha una vita relativamente corta, circa 8 ore.
Un client che è in possesso di un TGT valido farà le sue richieste di servizio al TGS e non più all’AS, almeno fino a quando il TGT non sarà scaduto. Le comunicazioni tra TGS e client saranno cifrate con la chiave di sessione Ks estratta dal TGT e non con la chiave segreta del client. Il TGS autenticherà il client, con il metodo visto precedentemente per l’autenticazione client/server, e rilascerà un Ticket e un’altra session key per la comunicazione client/server.
Infine le transizioni in arancio avverranno nel modo consueto utilizzando il Ticket e la session key di volta in volta concesse dal TGS.
Cross-Realm authentication
Il metodo fin qui descritto funziona fin tanto che sia il client che il server siano registrati sullo stesso Authentication server. Si definisce REALM l’insieme di users e di servers registrati con un particolare Authentication server.
Per poter permettere l’autenticazione tra REALM differenti è necessario introdurre una session key tra 2 differenti Authetication server detta cross-REALM key. Quando un client vuole autenticarsi ad un server di un altro REALM effettua una richiesta al proprio TGS, quest’ultimo riconosce che la richiesta si riferisce ad un altro REALM e fornisce al client un TGT per la richiesta al TGS remoto (questo TGT sarà cifrato con la chiave condivisa tra i 2 TGS). A questo punto il TGS remoto può autenticare il client e gli fornisce un Ticket per il server.
Si sottolinea la necessità dell’esistenza di una registrazione tra ogni Authentication server, cosa che si rivela inaccettabile su medie o grosse reti quali Internet. Nella versione 5 è stata introdotta una condivisione di chiavi gerarchica (“hierarchical sharing”) per limitare il numero di registrazioni da gestire.
Password To Key
Abbiamo visto che l’utente digita la propria password mentre il software client utilizza una chiave di cifratura simmetrica. In Kerberos, non esistono limitazioni sulla lunghezza della password scelta dall’utente, mentre molti algoritmi di cifratura utilizzano una chiave a lunghezza fissa.
La tecnica adottata per utilizzare la password dell’utente nelle operazioni di cifratura è basata su una conversione che trasforma la password in una chiave di cifratura simmetrica, questa operazione è implementata dalla funzione string2key.
L’approccio che si segue è quello di applicare una funzione HASH alla stringa composta concatenando la password dell’utente con un “SALT” il cui valore varia a secondo delle versioni di Kerberos e che serve a rendere la trasformazione sulla password dipendente dalla macchina sulla quale è effettuata.
Quindi per implementare lo scambio di messaggi visto prima tra AS, client e server, sono necessari tre elementi:
- una algoritmo di crittografia forte;
- una funzione HASH;
- una funzione che implementi il checksum per l’Authenticator;
Nelle prime versioni di Kerberos l’unico algoritmo crittografico supportato era il DES, associato ad esso vi erano una funzione HASH ottenuta dal DES in una particolare modalitàƒ operativa e l’algoritmo CRC-32 per il calcolo dei checksum.
Inoltre nelle versioni di Kerberos precedenti alla versione 5 non veniva utlizzato il SALT e quindi questo aveva un valore “NULLO”. Con la versione 5 di Kerberos è stato introdotto un maggiore livello di astrazione rispetto al passato, per cui virtualmente qualsiasi algoritmo crittografico è supportato, inoltre si potrebbe in teoria scegliere una qualsiasi funzione HASH per la conversione “password2key” ed un qualsiasi algoritmo per i checksum.
Di fatto però gli algoritmi disponibili attualmente sono:
- DES e Triplo DES per la crittografia
- hmac e CRC32 per i chksum
- sha1, md5 e la funzione derivata da DES-CBC per l’hash.
In particolare vediamo come è implementata la funzione Hash per la trasformazione da password a chiave quando l’algoritmo usato è il DES.
Essenzialmente questa funzione applica una trasformazione alla password dalla quale ottiene una chiave di 64 bit valida per il DES.
Qundi utilizza questa chiave per cifrare la password con il DES in modalitàƒ PCBC, che come vedremo è una modalità operativa derivata dalla modalità CBC che ha la caratteristica di “propagare” un eventuale errore a tutti i blocchi successivi a quello in cui si esso si è verificato.
In questo modo un errore in un passaggio produrrà sicuramente una chiave non valida.
La figura seguente illustra tale conversione:
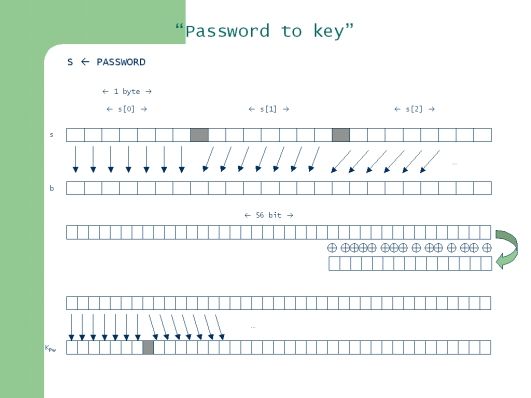
Inizialmente la password è memorizzata nella stringa di caratteri “s”. Si procede compattando la stringa “s” nella stringa di bit “b” copiando i primi 7 bit di ogni carattere, eliminando l’ottavo bit che in una chiave DES è il bit di parità . (questa operazione è giustificata dal fatto che in Kerberos 4 solo caratteri ASCII erano ammessi come password e i caratteri ASCII sono codificati con 7 bit quindi tagliando l’ottavo bit non si perdono informazioni).
Formalmente avviene questo:
b[0] = bit 0 di s[0] … b[6] = bit 6 di s[0] b[7] = bit 0 di s[1] … b[7i + m] = bit m di s[i] 0 <Â= m <Â= 6
La stringa cosଠottenuta viene ripiegata “a ventaglio” in blocchi da 56 bit, calcolando poi l’XOR tra i bit che si andranno a sovrapporre. Per esempio se la stringa è di 59 bit si avrà
b[55] = b[55] XOR b[56] b[54] = b[54] XOR b[57] b[53] = b[53] XOR b[58]
Abbiamo cosଠottenuto la chiave a 56-bit per il DES. Per essere conformi allo standard la stringa viene estesa nuovamente inserendo l’ottavo bit di parità ad ogni byte della stringa. Otteniamo in tal modo una chiave di cifratura di 64-bit che chiamiamo Kpw.
Questa è la chiave che verrà utilizzata col DES nella modalità operativa PCBC per cifrare la password e ottenere dalla cifratura un HASH che sarà usato come chiave segreta.
La modalità operativa PCBC del DES è strettamente derivata dalla più famosa modalità CBC. La modalità operativa del DES CBC, lo ricordiamo, effettua, ad ogni stadio della cifratura, l’XOR del testo in chiaro corrente e il precedente blocco di testo cifrato. Per la cifratura viene utilizzata sempre la stessa chiave.
La caratteristica di questa modalità è che lo stesso blocco di testo in chiaro, se ripetuto, produce differenti blocchi di testo cifrato. Inoltre se nell’atto della trasmissione si verifica un errore ad esempio nel blocco Ci, tale errore si propagherà nei blocchi di testo in chiaro Pi e P(i+1).
Con la modalità operativa PCBC invece un eventuale errore di trasmissione di un blocco cifrato si propagherà a tutti i successivi blocchi decifrati rendendo ogni blocco corrotto. In tal modo cifratura e integrità dei dati sono combinati in unica operazione.
La seguente figura descrive la modalità PCBC. Abbiamo evidenziato in rosso le differenze con la modalitàƒ classica CBC.
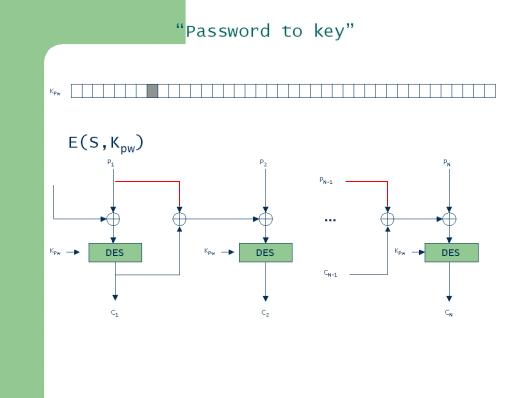
P1, P2…Pn sono blocchi di 64-bit che costituiscono la password dell’utente; se la lunghezza della password non è multipla di 64 verrà effettuato un padding.
IV è il vettore di inizializzazione e il suo valore dipende dalle implementazioni.
Kpw è la chiave DES per la cifratura a 64-bit (solo 56-bit significativi).
C1, C2,…Cn sono i blocchi di testo cifrato che rappresentano la password dell’utente modificata e cifrata, solo l’ultimo blocco però verrà memorizzato nel DB dell’AS come chiave segreta.
I Ticket
Continuiamo il nostro paragone tra Kerberos e autenticazione nella vita “reale”, tutti noi sappiamo che per i diversi servizi ai quali possiamo accedere come cittadini spesso sono previste autorizzazioni diverse. In altre parole ci sono autorizzazioni piò¹ durature come una “patente di guida” (che per esempio dura 10 anni) e autorizzazioni meno durature come un biglietto per il tram che per esempio può² durare un giorno oppure solo poche ore. Anche in Kerberos esiste una vasta gamma di autorizzazioni che corrispondono a diverse tipologie di Ticket, distinguiamo in particolare:
- Ticket iniziali;
- Ticket pre-autenticati;
- Ticket invalidi;
- Ticket postdatati;
- Ticket rinnovabili;
- “proxy” Ticket;
- “forwarded” Ticket;
Tickets iniziali
Alcuni servizi possono scegliere di accettare solo quei ticket che sono stati rilasciati direttamente dall’AS, perchè il loro rilascio è strettamente legato all’inserimento una password, invece di usare le informazioni in cache. Questi particolari ticket sono segnalati attraverso il flag INITIAL. Tipicamente, questa caratteristica è utilizzata per le comunicazioni dirette con un servizio, ma il flag può essere settato anche per i TGT rilasciati direttamente dall’AS. Comunque tutti i ticket rilasciati attraverso i TGT non hanno il flag INITIAL settato.
I ticket Pre-Autenticati
Il server AS chiede ai client di far di più che mandare solo un messaggio per dimostrare la loro identità . Per confermare che è stato usato qualche metodo di convalida prima del rilascio dei ticket iniziali, viene settato il flag PRE-AUTHENT. Se invece viene utilizzato un supporto hardware per convalidare l’utente (come le smart card) allora viene settato il flag HW-AUTHENT. Diversamente dal INITIAL flag, questi flag possono essere settati su qualunque ticket; se un ticket non è un ticket iniziale, allora esso eredita i valori di questi flag dal TGT.
Ticket Invalidi
Supponiamo che un utente voglia eseguire un lavoro batch di notte, e questo lavoro richieda ticket per accedere a vari servizi. L’utente, naturalmente, non vuole essere presente quando parte il lavoro ma non vuole neanche che i suoi ticket validi siano inutilizzati per tutto il giorno per ovvi motivi di sicurezza.
In tal caso l’utente può richiede a Kerberos di rilasciare ticket post-datati. Questi hanno il flag INVALID settato, per indicare che in quel momento non sono ancora validi. Nessun server è autorizzato ad accettare un ticket con il flag INVALID settato. Quando un client spedisce una richiesta al TGS, questo flag può essere modificato senza che l’utente sia presente. Questo meccanismo permette anche di invalidare ticket permanentemente se essi fossero rubati prima del loro periodo di validità .
Ticket Postdatati
Certamente non tutti i ticket sono postdatati, un TGT spedito al TGS dovrebbe avere il flag MAY-POSTDATE settato per indicare che il TGS dovrà rilasciare un ticket postdatato alla risposta. I ticket postdatati hanno il flag POSTDATED settato. I client non possono direttamente manipolare il ticket, essi devono richiedere il flag MAY-POSTDATE usando l’opzione ALLOW-POSTDATE nella richiesta del ticket. Si deve notare che non è il TGT postdatato, ma è il ticket ottenuto usando il TGT. L’utente non può richiedere un TGT postdatato.
Ticket rinnovabili
Alcune applicazioni hanno un periodo di esecuzione molto lungo, e durante tutto questo periodo possono richiedere di essere autenticate più volte. Mantenere in “vita” i ticket per un lungo periodo li espone ad un notevole rischio di furti. Per ovviare ciò l’utente può richiedere una serie di ticket con una breve validità , ma questo richiede di usare la chiave segreta dell’utente più volte e ciò è sempre pericoloso. Kerberos mette a disposizione degli utenti i ticket rinnovabili. Il flag RENEWABLE marca il ticket come rinnovabile. Come un normale ticket ha due orari che indicano l’orario di inizio validità e l’orario di scadenza finale. Durante questo periodo il ticket può essere rinnovato più volte ma mai oltre il suo orario di scadenza finale.
Esempio. Supponiamo che sono le 8:00, un utente ha un ticket che scade alle 9:00. Questo ticket ha anche un orario di scadenza finale, diciamo le 21:00. Secondo le impostazioni di default in Kerberos i ticket possono essere rinnovati di 8 ore alla volta. Quindi l’utente alle 9:00 può rinnovare il ticket di altre 8 ore potendolo utilizzare cosଠfino alle 17:00 (9:00 + otto ore). Alle 17:00, però, può rinnovarlo solo di altre 4 ore in quanto il ticket alle 21:00 scade totalmente, e al quel punto bisogna solo richiedere un altro ticket.
Proxy Ticket
Un client qualche volta potrebbe desiderare un servizio per un proprio scopo; questo servizio a sua volta richiede ticket per poter usufruire di altri servizi come se fosse il client. Questo è il caso quando il primo servizio ha privilegi d’accesso ad un altro servizio. Per permettere questo, può essere spedito un TGT con il flag PROXIABLE settato al servizio, il quale lo re-indirizza al secondo servizio. Per prevenire un cattivo uso di questo meccanismo, solo gli indirizzi di rete listati nel ticket possono usufruire di proxy ticket.
Il flag PROXIABLE non indica che è autorizzato a rilasciare un TGT, ma solo ticket regolari. Quando il TGS riceve un TGT con il flag PROXIABLE settato, può rilasciare un ticket per il secondo servizio con il flag PROXY settato. Questo secondo servizio può esaminare i ticket con questi flag settati, e richiedere all’agente del proxy di provvedere ad ulteriori autenticazioni.
Una forma di proxy, chiamata proxy ristretto, è la base del meccanismo per NetCheque, un sistema di pagamento elettronico.
Forwarded Ticket
I forwarded ticket sono come i proxy ticket, eccetto che essi possono autorizzare il rilascio dei TGT. I flag corrispondenti sono chiamati FORWARDABLE e FORWARDED.
Analisi e comparazioni
Kerberos non è l’unico sistema di autenticazione sicuro ad essere stato implementato e del protocollo Kerberos esistono diverse implementazioni sviluppatesi sopratutto quando la legge sulla esportazione del software crittografico dagli Stati Uniti era molto più restrittiva.
Inoltre l’obiettivo di rendere sicura la fase di autenticazione attraverso la crittografia per evitare che i dati in transito sulla rete siano “spiati” può essere raggiunto anche con software molto diversi da Kerberos. Vediamo quindi le limitazioni, i pregi di Kerberos e un breve confronto con altri sistemi
Pregi e difetti
Le principali limitazioni possono essere riassunte nei seguenti punti:
- Non protegge contro la possibilità di scoperta della password dell’utente
- Richiede un cammino sicuro attraverso il quale deve transitare la password dell’utente, inoltre richiede in genere una macchina dedicata e sicura come Authentication server
- Per poterlo utilizzare le applicazioni devono essere in parte riscritte, devono essere delle “Kerberized Applications”
– L’uso del DES è stato superato mediante l’introduzione di uno strato intermedio tra il sistema e gli algoritmi di crittografia che permettono l’adozione di qualsiasi algoritmo crittografico, tuttavia sussitono ancora conflitti con la legislazione degli USA
– Sebbene dal punto di vista dell’utente Kerberos sia totalmente trasparente, la sua installazione è tuttaltro che indolore. L’installazione di Kerberos è piuttosto “intrusiva” e necessita di un adattamento del sistema su cui gira che consiste nella modifica di diversi file di configurazione e nella sostituzione di gran parte dei “server” standard, il che a volte crea un conflitto con software già esistenti che non possono essere kerberizzati
Naturalmente esistono altri commenti negativi a Kerberos ma si ricorda che l’autenticazione deve essere un compromesso tra sicurezza e velocità e che quindi i miglioramenti che vengono indicati devono inserirsi in una più ampia visuale di una determinata realtà .
Differenze tra V4 e V5
Dalla versione 4 alla versione 5 sono stati introdotti molti miglioramenti sia all’implementazione che al protocollo, essi possono essere riassunti nei seguenti punti:
- I nomi dei Principal sono multi- componente piuttosto che del tipo user@host
- Nuovi flag nei ticket
- Autenticazione two- tgt user- to- user
- Sostituzione dell’algoritmo di cifratura
- Indipendenza dal tipo di indirizzo; vediamoli nei dettagli:
Ticket Flags
- Forwarding: (forwardable, forwarded)
- Proxying: (- able, – ied)
- Post- dating (may- , – ed, plus invalid)
- Renewable
- Initial
- Duplicate- session- key
Autenticazione Two- Tgt user- to- user
1 Usata quando il server non può² mantenere il segreto a lungo (workstation pubblica)
2 Il server usa il TGT dell’utente ottenuto al login e la chiave di sessione come base per la fiducia
3 Il client prende un TGT, manda il suo e quello del server al KDC e quindi procede normalmente
Nuove funzioni di cifratura
1. V4 ha solo il DES modificato in modo divertente
2. V5 ha essenzialmente una “funzione virtuale” per l’interfaccia di cifratura
3. Il codice del MIT fornisce il DES con CRC- 32 come un pacchetto separato
Address- type independency
1. Gli indirizzi sono codificati come {tipo, lunghezza, contenuto}
2. Gli indirizzi possono essere ignorati da una applicazione con un piccolissimo impatto sulla sicurezza.
3. Principalmente utile per combattere il furto delle credenziali
Differenze Implementative
1. “name space” separati, il codice V4 e quello V5 possono essere linkati nello stesso server.
2. Cache delle credenziali flessibile, server key, replay cache interfaces (“funzioni virtuali”)
3. Propria identificazione del replay
4. (eventualmente API generica)
Confronto con SSL
In generale il confronto tra SSL e Kerberos è il confronto tra il sistema di autenticazione a chiavi private con terza parte fidata contro quello a chiavi pubbliche basato sui certificati.
Come si nota subito SSL ha due maggiori vantaggi su Kerberos:
– SSL non richiede una terza parte fidata;
– esso può essere usato per stabilire una connessione sicura anche quando tra le due parti non esistono segreti come chiavi, password ecc..
Questi due vantaggi rendono SSL ideale per la comunicazione sul Web e per applicazioni simili.
Ovviamente anche SSL ha i suoi inconvenienti:
– Le chiavi revocate: se un certificato valido rilasciato ad un utente è compromesso e deve essere revocato, come fanno tutti i server con cui quell’utente interagisce a sapere che quel certificato non è più valido? Ogni revoca di certificati deve essere propagata a tutti i server più importanti più volte oppure i server verifica ogni volta i certificati entranti con il “revocation server”. In questo caso il server delle revoche deve essere disponibile ogni momento e comunque deve assicurare una comunicazione sempre efficiente essendo una terza parte necessaria, e con ciò si va a perdere uno dei maggiori vantaggi di SSL su Kerberos.
In Kerberos una chiave revocata può essere disabilitata attraverso il KDC e il ticket diventerà inutilizzabile a più presto senza nessuna operazione dei server.
– La sicurezza delle chiavi in SSL: quando si ottiene un certificato, esso risiederà sull’hard disk del sistema. Essendo cifrato con una password memorizzata nel sistema e vulnerabile ad eventuali attacchi di cracker. In Kerberos invece non c’è la necessità di ricerca di certificati per l’autenticazione, tranne che per la password che è nella testa dell’utente e non sull’hard disk.
– Costo di utilizzo: Kerberos è un pacchetto libero e può essere installato liberamente, mente SSL è licenziato e il suo utilizzo deve essere pagato.
– Open standard: Kerberos è nato free sin dall’inizio. I suoi standard sono documentati liberamente e sono stati sviluppati pubblicamente dall’inizio. Invece SSL fu sviluppato da una compagnia con un interesse commerciale in modo tale che il suo standard diventasse LO standard. Un ruolo importante lo fece Netscape per lo sviluppo degli standard su Internet.
– La flessibilità : Kerberos è più flessibile di SSL. Per esempio se si vuole aggiungere una nuova tecnologia di autenticazione a Kerberos (per esempio un nuovo tipo di Smart Card con il proprio algoritmo), l’unica cosa da fare è modificare il proprio KDC in modo tale da accettare questo nuovo tipo di autenticazione cosଠfacendo le applicazioni supporteranno automaticamente la nuova tecnologia. Invece se si vuole implementare una nuova tecnologia di autenticazione in SSL, è fortemente consigliato attendere il rilascio di una nuova versione di SSL che supporti quella tecnologia.
In conclusione non si può dire quale sistema di autenticazione sia più efficiente tra Kerberos e SSL. Una cosa sicura è che esistono applicazioni con cui Kerberos è più efficiente di SSL e viceversa.
Considerazioni Preliminari
Kerberos è destinato soprattutto a reti eterogenee e di dimensioni significative, per questo prima di installarlo è necessario fissare alcuni parametri fondamentali per una crescita “sana” e “naturale” della nostra rete. In particolare bisogna riflettere sui seguenti aspetti:
- Il nome del proprio Kerberos Realm (eventualmente potrebbero essere piò¹ di uno)
- Come mappare gli hostnames sui Kerberos Realm”
- Quali porte il KDC e il servizio di accesso al database (kadmin) useranno.
- quanti KDC secondari (SLAVE) sono necessari e dove essi debbano essere dislocati.
- L’hostname del KDC principale e di quelli secondari.
- La frequenza con cui il database si propagheràƒ dal KDC principale ai secondari.
- compatibilitàƒ tra Kerberos V4 e Kerberos V5.
Scelta dei “Realm”
Sebbene il “Kerberos Realm” possa essere una qualsiasi stringa ASCII, la convenzione corrente è quella di utilizzare lo stesso nome del dominio in lettere MAIUSCOLE.
Il Mapping degli hostnames sui “realms” può essere fatto in due modi.
Un primo approccio può essere quello basato sul file “krb5.conf”; qui è possibile definire un realm mediante delle semplici associazioni, associando ad un realm un intero dominio oppure un singolo hostname.
La definizione è dal generale al particolare, quindi si specifica il mapping prima per un dominio o sottodominio e poi si indicano le eccezioni a quel mapping.
Uno stralcio del file krb5.conf in cui si vede la sezione di dichiarazione dei realm
[realms]
SPARTACO.IT = {
kdc = tancredi:88
admin_server = tancredi:749
default_domain = IT
}
[domain_realm]
.it = SPARTACO.IT
it = SPARTACO.IT
tancredi.diareti.diaedu.unisa.it=SPARTACO.IT
tancredi.diareti.diaedu.unisa=SPARTACO.IT
tancredi.diareti.diaedu=SPARTACO.IT
tancredi.diareti=SPARTACO.IT
tancredi=SPARTACO.IT
Il secondo approccio, si avvale del servizio DNS, e lavora cercando le informazioni in record speciali, detti “TXT”. Se il meccanismo è abilitato, il client tenterà di trovare un record TXT che è formato concatenando la stringa “_Kerberos ” al nome dell’host in questione. Se questo record non è definito sarà usato “_Kerberos ” e il nome del dominio, quindi il nome del dominio padre e cosi via. Ad esempio per l’hostname ZOO.DIAEDU.UNISA.IT, il nome cercato sarà :
_Kerberos.zoo.diaedu.unisa.it _Kerberos.diaedu.unisa.it _Kerberos.unisa.it _Kerberos.it
Il valore del primo TXT trovato è preso e considerato come il nome del “REALM”. Inoltre è possibile usare i due sistemi in modo eterogeneo
Porte usate da Kerberos
Le porte usate di default da Kerberos sono la porta 88 per il KDC e la porta 749 per il server di amministrazione.
KDC secondari
I KDC secondari servono a fornire la continuità del servizio “ticket-granting” nel caso di inacessibilità del server principale. Il numero di KDC secondari e la loro collocazione fisica e logica, dipendono dalle caratteristiche della rete. Tutta la procedura di autenticazione di Kerberos su una rete richiede che ogni client sia in grado di contattare un KDC, quindi è necessario anticipare ogni possibile motivazione che possa rendere indisponibile un KDC e predisporre un KDC secondario che sia in grado di intervenire. Avere almeno un KDC secondario con funzioni di backup può essere fondamentale per prevenire “fermi” quando il KDC principale sarà down, in aggiornamento o comunque indisponibile.
Se una rete è partizionata avere un KDC secondario accessibile ad ogni segmento è molto utile; quindi se è possibile ci vorrebbe un KDC secondario in ogni edificio diverso da quello in cui gira il principale, questo previene tutti i vari problemi locali che si possono presentare.
A livello di configurazione, la soluzione più immediata per distinguere i vari KDC è quella di definire un insieme di CNAME (ossia di alias per gli hostname) seguendo uno schema simile:
- “Kerberos” per il KDC principale
- “Kerberos -1”, “Kerberos -2″, …, ” Kerberos -n” per tutti gli altri.
In questo modo poter scambiare un secondario e un principale è semplice basta solo cambiare questa voce nel DNS. Una alternativa per localizzare i KDC di un realm attraverso il DNS si basa sull’uso di un particolare “record”. Il DNS, infatti, supporta un record relativamente nuovo detto SRV, che indica l’hostname e il numero di porta per un determinato servizio eventualmente con pesi e priorità .
L’uso con Kerberos del record SRV e relativamente intuitivo. Il nome del dominio usato nel record SRV è il nome del Realm in stile “dominio”.
Esistono diversi servizi che possono essere configurati in questo modo i cui nomi sono:
_Kerberos ._udp: Serve a contattare ogni KDC, ò¨ la voce usata piò¹ di frequente ed ò¨ legata alle porta 88 e 750 su ogni KDC.
_Kerberos -master._udp: Questa voce si riferisce a quei KDC che non sono ancora stati aggiornati e hanno il database delle password in uno stato non consistente. Questo servizio è usato solo nel caso in cui l’utente si sta “loggando” e la password sembra scorretta; in questo caso il KDC principale viene contattato con gli stessi parametri e solo se anche questo login fallisce si ha l’errore di “password non valida”. Tuttavia se si ha un solo KDC oppure per qualsiasi altra ragione non ci sono KDC accessibili che possano recepire i cambiamenti velocemente non è necessario settare questa voce.
Altri servizi sono:
_Kerberos-adm._tcp: Questo indica la porta 749 sul KDC principale e viene utilizzato dal software ‘kadmin’ e dalle utility collegate.
_kpasswd._udp: Questo deve listare la porta 464 sul KDC principale. E’ usato quando un utente cambia la sua password. La specifica DNS SRV richiede che gli hostname elencati siano in forma canonica e non alias. Quindi, ad esempio, si potrebbero includere i seguenti record nella configurazione di un dns come BIND:
$ORIGIN spartaco.it. _Kerberos TXT SPARTACO.IT Kerberos CNAME pippo Kerberos-1 CNAME pluto Kerberos-2 CNAME paperino _Kerberos._udp SRV 0 0 88 pippo SRV 0 0 88 pluto SRV 0 0 88 paperino _Kerberos-master._udp SRV 0 0 88 pippo _Kerberos-adm._tcp SRV 0 0 749 pippo _kpasswd._udp SRV 0 0 464 pippo
Sia il meccanismo “DNS-based” per la determinazione dei REALM sia la distribuzione delle informazioni via DNS sono particolarmente consigliate nel caso in cui altri siti debbano interagire con il nostro tramite servizi “Kerberizzati”. L’uso massiccio dei file di configurazione al contrario è sconsigliato perchè rende difficili gli ampliamenti della rete dato che tutte le modifiche riguardano “tutti” gli host.
Propagazione del database
Il database Kerberos risiede sul KDC principale, e deve essere propagato regolarmente ai KDC secondari. In generale la frequenza con cui la propagazione deve avvenire dipende dal rapporto tra il tempo richiesto per la stessa e il massimo tempo che ragionevolmente un utente può attendere prima che un cambio di password abbia effetto. Se il tempo di propagazione è alto si può effettuare la propagazione in parallelo, trasferendo le informazioni dal KDC principale ad un sottoinsieme dei KDC secondari e poi lasciando che questi trasferiscano le informazioni “contemporaneamente” agli altri.
Compilazione dei sorgenti
A partire dalla versione 5B4 il sistema di configurazione dei sorgenti è stato prodotto utilizzando `autoconf’ della Free Software Foundation. La motivazione è quella di rendere più semplici la compilazione ed il porting su nuove piattaforme.
Requisiti
Per compilare Kerberos V5 sono richiesti 60-70 mega di spazio su disco, anche se questo fattore varia in base alla piattaforma ed alle opzioni di compilazione scelte.
Preparazione dei Sorgenti
Il primo passo, è ovviamente la decompressione dei pacchetti che contengono i sorgenti di Kerberos. In particolare la versione 5 è contenuta in un file in formato tar.gz che contiene i sorgenti. Il MIT non fornisce una versione precompilata e giàƒ installabile del pacchetto.
% mkdir krb5 % tar -zxvf `krb5-1.2.src.tar.gz'
Entrambi i files vanno decompressi nella stessa directory.
Compilazione
La prima scelta che va fatta in fase di compilazione è dettata dall’ambiente in cui si intende installare Kerberos.
Se la nostra rete è piuttosto omogena, cioè, tutti gli host girano sullo stesso tipo di piattaforma si può usare una singola gerarchia di directory che contenga sia i sorgenti che i files oggetto, compilare il tutto su una macchina e distribuire il “risultato” alle altre macchine, mentre se è necessario mantenere Kerberos per un grande numero di piattaforme sarà meglio adottare “gerarchie” separate per ogni piattaforma, in questo caso si riesce almeno a centralizzare la fase di compilazione.
E’ prevedibile che una rete basata su Kerberos sia piuttosto eterogenea, in questo caso il compito dell’amministratore di Kerberos è molto facilitato dall’adozione di autoconf perchè questo permette di centralizzare la compilazione per ognuna delle piattaforme presenti nella rete evitando di effettuare una compilazione diversa per ogni macchina.
sebbene il sistema sia fondamentalmente multipiattaforma, esistono comunque delle incompatibilità note tra Kerberos e alcuni sistemi. In questa breve guida, tuttavia, ci si limita ad analizzare il caso di un sistema Linux, verso il quale non esiste nessuna controindicazione, per cui ometteremo le incompatibilità verso altre piattaforme.
Se la nostra rete è costituita dallo stesso tipo di macchine con lo stesso sistema operativo su ogni host, l’operazione di compilazione si limita alla seguente procedura:
% cd /u1/krb5-1.2/src % ./configure % make
Tuttavia in una situazione reale è conveniente tenere differenti directory per i file oggetto di ogni piattaforma, o come si dice in gergo differenti “build tree”.
Questo è possibile con autoconf, a condizione di avere una versione di make che supporti una funzionalità detta `VPATH’ (il noto Gnu Make supporta VPATH).
(In realtà è possibile anche con implementazioni di MAKE che non supportano tale funzionalità , ma vanno usati tool aggiuntivi tipo ‘lndir’) Per esempio, se desideriamo creare un build tree per i file binari di Solaris potremmo usare la seguente procedura:
% mkdir /u1/krb5-1.2/solaris % cd /u1/krb5-1.2/solaris % ../src/configure % make
Configurazione dei Sorgenti
Dei 3 (o 4 comandi) elencati poc’anzi relativi alla compilazione, solo uno in effetti va commentato, il comando “configure”.
“configure” è uno script prodotto dal tool GNU Autoconf ed è ormai diventato quasi uno standard de-facto per la personalizzazione di un pacchetto sorgente sui vari Unix, Linux in testa.
“configure” è un tool che va eseguito rigorosamente sulla linea di comando, che accetta diversi parametri, alcuni “standard” e altri stabiliti dal creatore del pacchetto e quindi peculiari di quest’ultimo, nel nostro caso Kerberos.
L’utilità è quella di permettere all’utente di personalizzare il pacchetto abilitando o disabilitando una serie di funzionalità , scegliendo la destinazione dei files binari, il compilatore da usare etc, senza dover editare manualmente i makefiles, il che in progetti complessi può essere abbastanza arduo.
Ma vediamo alcune opzioni: –help: per chi non conosce “configure” la prima opzioni utile è senz’altro “–help”, essa produce l’effetto di listare le opzioni previste per questo pacchetto.
–prefix=PREFIX: Per default, Kerberos, installa i files del pacchetto a partire dalla directory /usr/local tuttavia è utile scegliere una radice diversa per questo pacchetto. Un esempio potrebbe essere la directory /opt/krb5.
Al di la della conformità allo standard FSH (lo standard che cerca di razionalizzare la gerarchia di directory di un sistema Unix ) questa scelta è preferibile perchè Kerberos è un pacchetto molto “invasivo”, la sua installazione richiede la sostituzione di molti “comandi” tradizionali di Unix, per questo separare i files Kerberizzati dalle versioni tradizionali rende più agevole una eventuale “de-kerberizzazione”, l’aggiornamento di Kerberos, e permette di continuare ad usare versioni non kerberizzate dei servizi, sebbene questo non renda la nostra rete sicura al 100% in alcuni casi potrebbe essere necessario per garantire la compatibilità ad applicazioni già esistenti che non sono in grado di sfruttare Kerberos, per contro non ci sono particolari svantaggi seguenti a questa separazione, a parte qualche modifica in più, come vedremo, al path di sistema e al percorso delle librerie.
–exec-prefix=EXECPREFIX: Con questa opzione si possono separare i programmi dai files di configurazione e dalla documentazione in linea.
–localstatedir=LOCALSTATEDIR: Permette di specificare una directory per i file di configurazione di Kerberos. Di default essi sono installati in PREFIX/var/krb5kdc, ma specificando questa opzione finiranno in: LOCALSTATEDIR/krb5kdc
–with-krb4: Abilità la compatibilità con Kerberos V4 usando il supporto interno alla nuova versione.
–without-krb4: Disabilita la compatibilità con Kerberos V4. Potrebbe essere utile se si pensa di non dover mai installare client che supportino solo la versione 4 di kerberos.
–with-vague-errors: Tra le ultime opzioni “particolari” vi è questa che ha lo scopo di soddisfare la legislazione americana fornendo messaggi vaghi di errore per non fornire informazioni ad un eventuale attaccante.
–enable-dns, –enable-dns-for-kdc, –enable-dns-for-realm: Abilitano l’uso del DNS per risolvere il nome degli host, quello dei Kerberos realm, oppure dei KDC, nel caso in cui le informazioni non siano presenti nei file krbd5.conf
Per esempio, per configurare Kerberos su una macchina Solaris usando il compilatore `suncc’ con le ottimizzazioni abilitate, basterà eseguire lo script con le seguenti opzioni:
% ./configure --with-cc=suncc --with-ccopts=-O
In aggiunta allo script “configure” esiste anche un file di configurazione che è possibile editare per personalizzare alcuni parametri di compilazione:`include/krb5/stock/osconf.h’. ecco alcune delle variabili più interessanti:
- DEFAULT_PROFILE_PATH: Indica il pathname per i file che contengono i profili per i realms noti, i loro KDC etc,etc.
- DEFAULT_KEYTAB_NAME: Il tipo e il pathname del file “Keytab” di default per il server che stiamo compilando.
- DEFAULT_KDC_ENCTYPE: L’algoritmo crittografico usato di default dal KDC.
- DEFAULT_KDB_FILE: Il punto del filesystem in cui ò¨ situato il database.
Test
Se la fase di compilazione ha successo, è possibile testare il risultato utilizzando i test di regressione contenuti in Kerberos V5. Per effettuare i test è necessario impartire i seguenti comandi, come si vede è piuttosto semplice:
% make check
In realtà alcuni test necessitano dei privilegi di root ed alcuni sono basato sul Framework DejaGnu. Per questi test è necessario disporre di tool aggiuntivi, che tuttavia sono comunemente disponibili sui vari Unix(R) come l’interprete Perl
Installazione
Infine, una volta effettuata la configurazione correttamente, la compilazione consiste sostanzialmente nei seguenti passi:
% cd /u1/krb5-1.2/src % make all % make install DESTDIR=destinazione-scelta
Configurazione
Proviamo a realizzare un dominio Kerberos sulla nostra rete che sia “minimale” ma sufficientemente funzionante. Nei paragrafi successivi non parleremo più di AS e di TGS, perchè nella implementazione software di Kerberos questi due componenti sono fusi in un unico server che svolge entrambe le funzioni. Questa componente si chiama KDC acronimo di “Key Distribution Center”
Installare un KDC
Scegliere una macchina come KDC è un compito delicato, la macchina scelta sarà la chiave della sicurezza dell’intera rete.
Quindi deve avere il massimo di sicurezza, e quindi soddisfare almeno i seguenti requisiti:
- Il server deve essere fisicamente sicuro.
- Il sistema operativo deve essere aggiornato con le ultime patch applicate.
- Non ci devono essere account sulla macchina eccetto che per l’amministratore Kerberos.
- Dovrebbe essere una macchina dedicata e quindi solo il KDC dovrebbe girare su questa macchina.
- E’ ideale poter disporre di macchine aggiuntive che possano fungere da server secondari per ovviare a guasti hardware e per bilanciare il carico della rete.
Configurare il KDC
Il primo passo per la configurazione del KDC è sicuramente la lettura dei tre manuali di kerberos (Manuale utente, amministratore ed installazione) che sono presenti nel pacchetto sorgente.
Tuttavia le operazioni di configurazione più che essere complesse, risultano laboriose e richiedono una discreta conoscenza del sistema Unix (almeno quando si installa il software per questo sistema).
Tutto questo perchè Kerberos è molto intrusivo e per essere configurato richiede un certo “adattamento” del sistema ad esso.
Creazione del file di configurazione
I file di configurazione per il KDC sono krb5.conf e kdc.conf.
krb5.conf deve essere situato nella directory /etc mentre la collocazione del file kdc.conf può essere speficificata nel file krb5.conf. Ogni files è costituito da una serie di sezioni indicate tra parentesi quadre ed una serie di espressioni del tipo “opzioni = valore” il file krb5.conf è composto da 7 sezioni che sono:
- Libdefault: impostazioni per la libreria
- Appdefalut: impostazioni per le applicazioni
- Realms: impostazioni per i singoli realm
- Domain_realm: mapping domainname->realm
- Logging: impostazioni funzioni di log

